Robots don’t fail because they can’t move— they fail because we didn’t teach them what “unsafe” looks like.
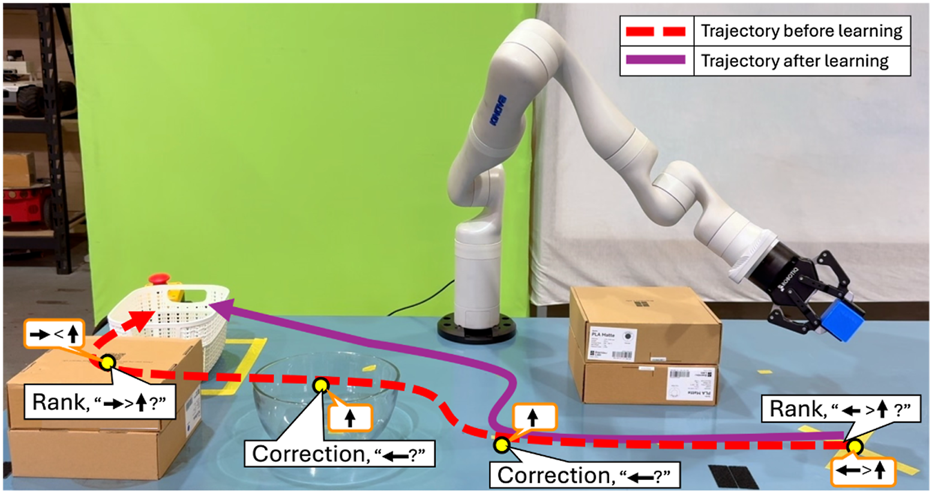
This Frontiers in Robotics and AI paper proposes Adaptive Feedback Selection (AFS): instead of always asking humans for the same kind of input (approval, corrections, etc.), the robot chooses when to query and which feedback format to ask for, balancing information gain vs. user effort/cost. The objective is to learn a penalty model for negative side effects (NSEs) so robots stop optimizing the task while causing collateral damage.
A concrete benchmark signal: in the Safety-Gym Push setting, AFS drives the average penalty to ≈0 across query budgets (400–2500), while a naive agent is around ≈120 penalty at B=400 (read off Figure 7; unitless penalty). This is exactly the kind of behavior shift you want before putting robots near people, tools, or inventory.
How I’d pilot this in 10 business days
- Instrument “NSE events” (collisions, near-misses, unsafe zones) and compute a simple penalty score.
- Implement 2–3 feedback modes (quick approval, severity label, occasional correction) with timestamps and operator effort tracking.
- Run an A/B test: fixed querying vs. AFS-style querying under the same operator time budget, compare NSE penalty and task completion metrics.